


The first post in this series went over some fundamental concepts and interfaces you will encounter as a developer using Spring Batch. Now, let's build on those ideas to construct a full batch pipeline. Hopefully this can serve as a reference for how quickly a Java developer can build batch jobs.
Prerequisites
- Spring framework
- Spring Batch fundamentals. I recommend using the last post in this series as a crash-course in tandem with Spring's docs
- Databases i.e basic relational database concepts
The full, completed source code can be found here. Below we'll construct the job piece by piece.
The scenario
I'm sure you're aware of Stack Exchange, but did you know the people over at Stack Exchange, Inc publish all content as scheduled data dumps? We're going to take these public records and ingest them into a relational database to demonstrate development with Spring Batch.
The job will ingest everything in a site on StackExchange (posts, comments, users, etc) into a MySQL database. Using Spring Batch we can create a maintainable and extensible Job usign a minimal amount of code.
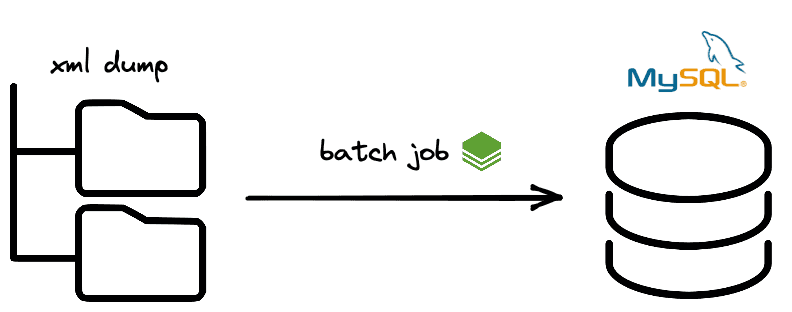
The datamodel
Stack Exchange publishes each site in individual archives. They all follow the same relational schema that can be translated to MySQL. The datamodel for an individual site on the Stack Exchange network can be reduced to a few models: Posts, Comments, Users, Badges, Votes, and Post History.
The schema we'll be using to define a stack exchange site can be found here.
Setting up the project & reading data
A starting point for many batch jobs is the delivery of a file. In this exercise, the job will read XML files in a target directory. To set that up, we can download our input data from here.
I started with a fresh clone of the spring-batch-rapid-starter project. It comes with some basic datasource configurations and an opinionated organization of a Spring Batch project. I downloaded and extracted the dataset to the resources folder to get a clean template for the batch job. I chose to download the dump from health.stackexchange.com:
src/main/resources
├── application.yaml
├── import
│ └── health.stackexchange.com
│ ├── Badges.xml
│ ├── Comments.xml
│ ├── PostHistory.xml
│ ├── PostLinks.xml
│ ├── Posts.xml
│ ├── Tags.xml
│ ├── Users.xml
│ └── Votes.xmlFor the sake of brevity we won't unzip the dump with code; however, it could be done in a Tasklet. In fact, there are some great examples of doing so like the one I found in Spring Batch Toolkit.
The template project comes pre-wired with configuration in application.yaml and the package com.batch.config.db that the batch framework needs. Behind the scenes Spring Batch logs metadata and job output to a database. To keep things simple we'll point the framework to log to an in-memory Hyper SQL database:
spring:
cloud:
task:
initialize-enabled: true
batch:
fail-on-job-failure: true
batch:
initialize-schema: always
datasource:
driver-class-name: org.hsqldb.jdbc.JDBCDriver
url: "jdbc:hsqldb:mem:testdb;DB_CLOSE_DELAY=-1"
username: "user"
password: "pass"Out of the box there are some sample readers and writes in the package com.batch.config.readers for testing that aren't needed, so clear those out. With a blank project, let's work on reading and printing the data we've downloaded.
Adding POJOs for the domain objects
Since we already know the full datamodel, we can use it to define all the entities as POJOs following pretty standard Spring JPA conventions. For example, the basic comments entity we'll start with looks like this:
@Data
@Entity(name = "comments")
@AllArgsConstructor
@NoArgsConstructor
public class Comment {
@Id
private BigInteger id;
private BigInteger postId;
private Integer score;
private String text;
private String creationDate;
private String userDisplayName;
private BigInteger userId;
private String contentLicense;
}Each of the other objects follows a similar pattern, and all the models can be found here. With entity definitions in hand, we can work on mapping inputs and outputs to them.
Reading and parsing XML records in batch
Spring Batch and the community have written many readers and writers for common use cases. For reading XML, the StaxEventItemReader meets most requirements. As the docs describe:
The StaxEventItemReader configuration provides a typical setup for the processing of records from an XML input stream.
In our scenario, XML 'records' we are targeting are all in a similar form. The first few rows in posts.xml look like this:
<?xml version="1.0" encoding="utf-8"?>
<posts>
<row Id="2" PostTypeId="1" AcceptedAnswerId="14" CreationDate="2015-03-31T19:00:01.793" Score="41" ViewCount="40838" Body="<p>The following tooth cracks are noticeable when a torch is shining on them (without the torch, they aren't visible). Are they serious? How viable are the teeth, and might they need to be replaced with false teeth in the near future? There is no pain experienced, but they seem to look quite bad:</p>

<p><img src="https://i.stack.imgur.com/2sgis.jpg" alt="Teeth 1">
<img src="https://i.stack.imgur.com/k3R8j.jpg" alt="Teeth 2"></p>
" OwnerUserId="8" LastEditorUserId="8" LastEditDate="2015-03-31T19:33:14.567" LastActivityDate="2019-12-22T04:22:54.330" Title="What are these lines in teeth?" Tags="<dentistry>" AnswerCount="1" CommentCount="1" FavoriteCount="3" ContentLicense="CC BY-SA 3.0" />
<row Id="3" PostTypeId="1" CreationDate="2015-03-31T19:06:32.503" Score="14" ViewCount="211" Body="<p>(By 'fortified', I refer to this definition: <a href="http://www.oxforddictionaries.com/definition/english/fortify?q=fortified" rel="nofollow noreferrer">increase the nutritive value of (food) by adding vitamins</a>.)</p>

<p>Are there any differences between calcium supplements (as pills or tablets), and foods fortified with calcium (e.g., artificially added to products such as soy milk)? </p>

<p>Isn't the solid calcium carbonate in supplements chemically the same as aqueous calcium carbonate in fortified drinks? I'm lactose-intolerant. Alas, purely natural foods don't contain enough calcium for the Recommended Daily Intake. </p>

<hr>

<p><strong>Optional Reading and Addendum:</strong> </p>

<blockquote>
 <p><a href="http://www.webmd.com/osteoporosis/features/calcium-supplements-pills?page=2" rel="nofollow noreferrer">1. WebMD</a>: "Keep in mind that there's really not that much difference between getting calcium in a supplement and calcium in food."<br>
 "Calcium-fortified foods -- such as cereals, some juices, and soy milk -- are excellent sources of the mineral, experts tell WebMD."</p>
 
 <p><a href="http://www.health.harvard.edu/blog/high-calcium-intake-from-supplements-linked-to-heart-disease-in-men-2013020658610" rel="nofollow noreferrer">2. health.harvard.edu</a>: An 8-ounce portion of off-the-shelf orange juice contains about 300 mg of calcium. The calcium in fortified soy milk also compares favorably to whole milk.
 Breakfast cereals (which are also fortified) contain substantial amounts of calcium, especially when combined with low-fat milk.
 A portion of oatmeal on its own contains just 100 mg of calcium. “But if you cut up some dried figs and add it to a bowl of oatmeal with milk, you easily get about half of what you need without having any supplements,” Dr. Hauser says.</p>
 
 <p><a href="http://well.blogs.nytimes.com/2013/04/08/thinking-twice-about-calcium-supplements-2/?_r=0" rel="nofollow noreferrer">3. NY Times Blog</a>, <a href="http://www.nytimes.com/2011/01/25/health/25brody.html" rel="nofollow noreferrer">4. NY Times</a></p>
</blockquote>

<p>Footnote: I originally posed this <a href="https://biology.stackexchange.com/q/10429/4466">at Biology SE</a>. </p>
" OwnerUserId="14" LastEditorUserId="-1" LastEditDate="2017-04-13T12:48:15.073" LastActivityDate="2015-04-01T00:01:10.120" Title="Calcium supplements versus "fortified with calcium"" Tags="<nutrition>" AnswerCount="1" CommentCount="0" ContentLicense="CC BY-SA 3.0" />
<row Id="4" PostTypeId="1" CreationDate="2015-03-31T19:11:24.947" Score="32" ViewCount="911" Body="<p>One of the most often-cited facts about human life, compared to those of other animals, is that the main reason we live so much longer is modern medicine. Because we can treat illnesses that would previously affect lifespan, we are far more likely to live greatly extended lifespans. However, this leads to two possible (conflicting) logical conclusions:</p>

<ol>
<li>People who by chance didn't get deadly diseases before modern medicine would live as long as people today, meaning the ability for any <em>individual</em> to survive ninety or more years, far longer than nearly all animals, is unrelated to modern medicine.</li>
<li>Every illness one experiences weakens the body in some way, robbing it of future years. This would mean the role of modern medicine in extending lifespan is treating these illnesses to prevent the gradual reduction in lifespan.</li>
</ol>

<p>If the first is true, then lifespan itself isn't influenced by modern medicine unless it prevents death as the direct result of a disease, and only <em>average</em> lifespan is affected. In other words, if nine in ten dies at age thirty due to a deadly disease, and one in ten dies at age eighty by avoiding disease, the average life expectancy is thirty five, even though an individual could by living an extremely careful life survive to reach eighty.</p>

<p>If the second is true, then short periods of non-deadly illnesses experienced by everyone each shorten life expectancy by a tiny amount, together decreasing <em>everyone's</em> lifespan to the same thirty five, rather than the effect being a result of averages.</p>

<p><strong>So does each illness shorten lifespan, or is it only a result of averages that lifespan was so low pre-modern medicine, and humans always had the capacity for exceptionally-long lives?</strong></p>
" OwnerUserId="11" LastActivityDate="2017-01-16T14:14:31.053" Title="If human life is so long largely due to modern medicine, does every illness shorten lifespan?" Tags="<life-expectancy><disease><statistics>" AnswerCount="2" CommentCount="3" ContentLicense="CC BY-SA 3.0" />
To process this, we need to configure the StaxEventItemReader with a minimum of:
- Root element name: the name of the base element with the object to be mapped. Above, each
Postis an individualrowelement. - Resource: the spring resource pointing to a file or location with files to read.
- Unmarshaller: A Spring OXM interface used to map an XML fragment to an object.
Specifying this information using fluent builder syntax looks like this:
@Bean
public StaxEventItemReader postsReader() {
Jaxb2Marshaller unmarsh = new Jaxb2Marshaller();
unmarsh.setClassesToBeBound(Post.class);
return new StaxEventItemReaderBuilder<Post>()
.name("postReader")
.resource(new FileSystemResource("src/main/resources/import/health.stackexchange.com/Posts.xml"))
.addFragmentRootElements("row")
.unmarshaller(unmarsh)
.build();
}Above we create a StaxEventItemReader named postReader that operates on elements named row using the Jaxb2Marshaller (a generic marshaller/unmarshaller using the Java Architecture for XML Binding a.k.a JAXB spec). We're also binding the Post class defined above to the unmarshaller instance unmarsh.
We need to do one more thing before reading XML, and that is annotate the POJO entities we defined with some metadata required for deserialization. You'll notice the addition of a few annotations. XmlRootElement specifies the name of individual elements in a document and XmlAttribute specifies how to map to fields in the class. Lastly, XmlAccessorType is used to determine how to marshal to/from XML, and we specify that XmlAccessType.FIELD to signify that each field should be found to XML:
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.xml.bind.annotation.XmlAccessType;
import javax.xml.bind.annotation.XmlAccessorType;
import javax.xml.bind.annotation.XmlAttribute;
import javax.xml.bind.annotation.XmlRootElement;
import java.math.BigInteger;
@Data
@Entity(name = "badges")
@AllArgsConstructor
@NoArgsConstructor
@XmlRootElement(name = "row")
@XmlAccessorType(XmlAccessType.FIELD)
public class Badge {
@Id
@XmlAttribute(name = "Id")
private BigInteger id;
@XmlAttribute(name = "UserId")
private BigInteger userId;
@XmlAttribute(name = "Name")
private String name;
@XmlAttribute(name = "Date")
private String date;
@XmlAttribute(name = "Class")
private Integer badgeClass;
@XmlAttribute(name = "TagBased")
private Boolean tagBased;
}At this point we can use this ItemReader in a Step and start ingesting XML rows of post data backed by entities.
Before doing that, let's clean up our reader definition and parameterize some configuration info to make the job a bit more robust. We can extract the file name and path to Spring properties, and reference in our configuration class ReadersConfig. In application.yaml add properties pointing to the input data:
import:
file:
dir: "import/health.stackexchange.com"
posts: "Posts.xml"
comments: "Comments.xml"
badges: "Badges.xml"
postHistory: "PostHistory.xml"
users: "Users.xml"
votes: "Votes.xml"I also chose to lay the groundwork for ingesting multiple XML files of posts with a MultiResourceItemReader. This is totally optional, but by passing types of ResourcePatternResolvers to the MultiResourceItemReader the framework can easily read one or more directories. I set up the basis for this but am only pointing to a single file resource for now to save space. The refactored post reader definition looks like this:
@Configuration
@PropertySource("classpath:application.yaml")
public class ReadersConfig {
@Value("${import.file.dir}")
private String dir;
@Value("${import.file.posts}")
private String postsFile;
@Bean
public ItemReader multiPostsReader() {
Resource[] resources = null;
Resource fileSystem = new FileSystemResource(dir + "/" + postsFile);
resources = new Resource[] {fileSystem};
MultiResourceItemReader<String> reader = new MultiResourceItemReader<>();
reader.setResources(resources);
reader.setDelegate(postsReader());
return reader;
}
@Bean
public StaxEventItemReader postsReader() {
Jaxb2Marshaller unmarsh = new Jaxb2Marshaller();
unmarsh.setClassesToBeBound(Post.class);
return new StaxEventItemReaderBuilder<Post>()
.name("postReader")
.addFragmentRootElements("row")
.unmarshaller(unmarsh)
.build();
}
}Now let's print some data with this reader! I grabbed this slick ConsoleItemWriter from Spring Batch Toolkit to use as the writer in a test step. It 'writes' by logging to the console.
/**
* Logs each content item by reflection with the {@link ToStringBuilder#reflectionToString(Object)}
* method.
*
* @author Antoine
* @param <T>
*/
public class ConsoleItemWriter<T> implements ItemWriter<T> {
private static final Logger LOG = LoggerFactory.getLogger(ConsoleItemWriter.class);
@Override
public void write(List<? extends T> items) throws Exception {
LOG.trace("Console item writer start");
for (T item : items) {
LOG.info(ToStringBuilder.reflectionToString(item));
}
LOG.trace("Console item writer end");
}
}In the class WritersConfig let's define a method consoleItemWriter to create an instance of the writer to use in a step definition.
@Configuration
@PropertySource("classpath:application.yaml")
public class WritersConfig {
@Bean
public ConsoleItemWriter consoleItemWriter() {
return new ConsoleItemWriter();
}
}With reader and writer instances defined, the next step is to create the Step. The template should have already injected ReadersConfig and WritersConfig instances for use in the class BatchConfig. Defining the step to read and print post XML data is relatively straightforward with fluent syntax:
@Bean
public Step printPosts() {
return stepBuilderFactory
.get("posts")
.<Post, Post>chunk(BATCH_CHUNK_SIZE)
.reader(readers.multiPostsReader())
.writer(writers.consoleItemWriter())
.faultTolerant()
.build();
}Functionally, this creates a chunk-based step with a reader that delegates work to the StaxEventItemReader we defined for posts and writes output to the console. Now we can define a single-step job that when started will read Posts.xml and log to the console. The full job configuration to print post XML looks like this:
@Configuration
@EnableBatchProcessing
@EnableTask
public class BatchConfig {
public static final int BATCH_CHUNK_SIZE = 500;
public TaskConfigurer taskConfigurer;
public final JobBuilderFactory jobBuilderFactory;
public final StepBuilderFactory stepBuilderFactory;
/** Holds all readers available for job */
private final ReadersConfig readers;
/** Holds all writers available for job */
private final WritersConfig writers;
@Autowired
public BatchConfig(
JobBuilderFactory jobBuilderFactory,
StepBuilderFactory stepBuilderFactory,
TaskConfigurer taskConfigurer,
ReadersConfig readers,
WritersConfig writers) {
this.jobBuilderFactory = jobBuilderFactory;
this.stepBuilderFactory = stepBuilderFactory;
this.taskConfigurer = taskConfigurer;
this.readers = readers;
this.writers = writers;
}
@Bean
public Step printPosts() {
return stepBuilderFactory
.get("posts")
.<Post, Post>chunk(BATCH_CHUNK_SIZE)
.reader(readers.multiPostsReader())
.writer(writers.consoleItemWriter())
.faultTolerant()
.build();
}
@Bean
public Job importStackDumpToSql(Step printPosts) {
return jobBuilderFactory
.get("stackDump2SQL")
.incrementer(new RunIdIncrementer())
.start(printPosts)
.build();
}
}Compiling and running the job results in Posts being printed to the console in rapid succession. Success!
2022-02-09 08:01:23.653 INFO 4683 --- [main] com.snimma1.custom.ConsoleItemWriter : com.snimma1.model.Post@7cab8d52[id=5181,postType=1,acceptedAnswerId=5192,parentId=<null>,score=4,viewCount=59,body=<p>The study <a href="http://www.ncbi.nlm.nih.gov/pubmed/11697022" rel="nofollow">Preventing the common cold with a garlic supplement: a double-blind, placebo-controlled survey</a> shows a reduction of days challenged virally by about 70% just by taking 180mg allicin every day.</p>
2022-02-09 08:01:23.645 INFO 4683 --- [main] com.snimma1.custom.ConsoleItemWriter : com.snimma1.model.Post@4c5c0306[id=5130,postType=1,acceptedAnswerId=<null>,parentId=<null>,score=5,viewCount=98,body=<p>Most people would say that eating fruit is good for us; vitamins, micro-nutrients, phyto-chemicals.</p>Having validated that the StaxEventItemReader we created works for post data, the definitions for reading the other Stack Exchange domain objects can be written with the same set of steps.
Simply define a Bean of type StaxEventItemReader that is bound to the POJO representing the data, and use it as the delegate in another MultiResourceItemReader pointing to the data on the local filesystem. The final reader definitions for posts, comments, badges, post history, users, and votes are defined here.
Connecting & writing to MySQL
If you recall, a chunk-oriented step must read from at least one input and write to at least one output. So far we've constructed wiring to read our target data from XML and write to the console. Now let's close the loop and write to a relational database.
Before defining the ItemWriters for the job, let's get an instance of MySQL up and running. This can be done many ways. The simplest for local development nowadays is via a container. Using docker we can start an instance of MySQL as follows:
docker run --name test-mysql -e MYSQL_ROOT_PASSWORD=password -e MYSQL_ROOT_USER=root -e MYSQL_PASSWORD=password -d -p 3306:3306 mysql:5.7.26I happen to be running apple silicon and the typical mysql image doesn't work. As a workaround I ended up using this mysql-server image without issue.
Once your instance of MySQL is running, the last setup step is to create the target database and execute the schema. I created a database stacke and executed the full schema here to get a set of empty tables to populate via the batch job.
With a running database and empty schema let's make the working batch application aware of it by adding an additional data source. The rapid-starter template already has taken care of most of the boilerplate to do so. Configuring the app.datasource properties with our MySQL details in application.yaml will do the job:
app:
datasource:
dialect: org.hibernate.dialect.MySQLDialect
driver-class-name: org.mariadb.jdbc.Driver
url: jdbc:mysql://${MYSQL_HOST:localhost}:3306/stacke
username: ${MYSQL_USER:batch}
password: ${MYSQL_PWD:password}You may also notice the rapid-starter & package com.batch.config.db sets up spring-data-jpa. This will come in handy shortly... To verify succesful configuration, go ahead and start up the application. You should see some new output this time similar to below if everything worked:
2022-03-06 INFO 50201 --- [main] o.hibernate.jpa.internal.util.LogHelper: HHH000204: Processing PersistenceUnitInfo [name: appPersU]
2022-03-06 INFO 50201 --- [main] org.hibernate.Version: HHH000412: Hibernate ORM core version 5.4.25.Final
2022-03-06 INFO 50201 --- [main] o.hibernate.annotations.common.Version: HCANN000001: Hibernate Commons Annotations {5.1.2.Final}
2022-03-06 INFO 50201 --- [main] org.hibernate.dialect.Dialect: HHH000400: Using dialect: org.hibernate.dialect.MySQLDialect
2022-03-06 INFO 50201 --- [main] o.h.e.t.j.p.i.JtaPlatformInitiator: HHH000490: Using JtaPlatform implementation: [org.hibernate.engine.transaction.jta.platform.internal.NoJtaPlatform]
2022-03-06 INFO 50201 --- [main] j.LocalContainerEntityManagerFactoryBean: Initialized JPA EntityManagerFactory for persistence unit 'appPersU'
2022-03-06 INFO 50201 --- [main] o.hibernate.jpa.internal.util.LogHelper: HHH000204: Processing PersistenceUnitInfo [name: springPersU]
2022-03-06 INFO 50201 --- [main] org.hibernate.dialect.Dialect: HHH000400: Using dialect: org.hibernate.dialect.HSQLDialect
2022-03-06 INFO 50201 --- [main] o.h.e.t.j.p.i.JtaPlatformInitiator: HHH000490: Using JtaPlatform implementation: [org.hibernate.engine.transaction.jta.platform.internal.NoJtaPlatform]
2022-03-06 INFO 50201 --- [main] j.LocalContainerEntityManagerFactoryBean: Initialized JPA EntityManagerFactory for persistence unit 'springPersU'
2022-03-06 WARN 50201 --- [main] o.s.b.c.c.a.DefaultBatchConfigurer: No transaction manager was provided, using a DataSourceTransactionManager
2022-03-06 INFO 50201 --- [main] o.s.b.c.r.s.JobRepositoryFactoryBean: No database type set, using meta data indicating: HSQL
2022-03-06 INFO 50201 --- [main] o.s.b.c.l.support.SimpleJobLauncher: No TaskExecutor has been set, defaulting to synchronous executor.
2022-03-06 INFO 50201 --- [main] com.snimma1.Application: Started Application in 2.004 seconds (JVM running for 2.229)To write batches to MySQL, we need to define ItemWriters using the Datasource we just configured. There are a number of valid ways to do this. For example, we could write a custom ItemWriter by injecting the MySQl DataSource into our implementation. However, we can save some time by leveraging the the JpaItemWriter implementation that comes with Spring Batch. We can create a single instance of a JpaItemWriter with the persistance context for the app.datasource and use it to write each entity (i.e post, comment, etc) to MySQL. Since the rapid-starter has already setup spring-data-jpa, we just need to inject the EntityManager associated with app.datasource to create a working writer. Our complete WritersConfig looks like this:
@Configuration
@PropertySource("classpath:application.yaml")
public class WritersConfig {
@Bean
public ConsoleItemWriter consoleItemWriter() {
return new ConsoleItemWriter();
}
@Bean
public JpaItemWriter jpaItemWriter(
@Qualifier("appEntityManager") LocalContainerEntityManagerFactoryBean factory) {
JpaItemWriterBuilder builder = new JpaItemWriterBuilder();
return builder.entityManagerFactory(factory.getObject()).build();
}
}With some minor modifications to the job configuration class BatchConfig we can test dataflow end-to-end. After swapping out the ConsoleItemWriter, the job's configuration looks like this:
@Configuration
@EnableBatchProcessing
@EnableTask
public class BatchConfig {
public static final int BATCH_CHUNK_SIZE = 500;
public TaskConfigurer taskConfigurer;
public final JobBuilderFactory jobBuilderFactory;
public final StepBuilderFactory stepBuilderFactory;
/** Holds all readers available for job */
private final ReadersConfig readers;
/** Holds all writers available for job */
private final WritersConfig writers;
@Autowired
public BatchConfig(
JobBuilderFactory jobBuilderFactory,
StepBuilderFactory stepBuilderFactory,
TaskConfigurer taskConfigurer,
ReadersConfig readers,
WritersConfig writers) {
this.jobBuilderFactory = jobBuilderFactory;
this.stepBuilderFactory = stepBuilderFactory;
this.taskConfigurer = taskConfigurer;
this.readers = readers;
this.writers = writers;
}
@Bean
public Step step1(
@Qualifier("appEntityManager") LocalContainerEntityManagerFactoryBean factory) {
return stepBuilderFactory
.get("posts")
.<Post, Post>chunk(BATCH_CHUNK_SIZE)
.reader(readers.multiPostsReader())
.writer(writers.jpaItemWriter(factory))
.faultTolerant()
.build();
}
@Bean
public Job importStackDumpToSql(Step step1) {
return jobBuilderFactory
.get("writePosts")
.incrementer(new RunIdIncrementer())
.start(step1)
.build();
}
}Running this and checking the output we get ... an error?!:
.
.
2022-03-06 INFO 54620 --- [ main] com.snimma1.processor.PostProcessor : Processed post with title Can food be addictive?
2022-03-06 INFO 54620 --- [ main] com.snimma1.processor.PostProcessor : Processed post with title What are these lines in teeth?
2022-03-06 ERROR 54620 --- [ main] o.s.batch.core.step.AbstractStep : Encountered an error executing step posts in job stackDump2SQL
org.springframework.retry.ExhaustedRetryException: Retry exhausted after last attempt in recovery path, but exception is not skippable.; nested exception is javax.persistence.TransactionRequiredException: no transaction is in progress
at org.springframework.batch.core.step.item.FaultTolerantChunkProcessor$5.recover(FaultTolerantChunkProcessor.java:429) ~[spring-batch-core-4.2.5.RELEASE.jar:4.2.5.RELEASE]
at org.springframework.retry.support.RetryTemplate.handleRetryExhausted(RetryTemplate.java:512) ~[spring-retry-1.2.5.RELEASE.jar:na]
.
.This one confused me initially because everything above looks like it should write Posts to MySQL. After a bit of research, it turns out Spring Batch uses a TransactionManager under the hood to write job progress and metadata. It will not share this by default. And this makes sense! If the batch logic fails then only batch data should be rolled back and not important logging details and metadata. To solve this we simply need to explicitly pass the appTransactionManager (already created via the template project) to the step definition like so:
@Bean
public Step step1(
@Qualifier("appJpaTransactionManager") JpaTransactionManager transactionManager,
@Qualifier("appEntityManager") LocalContainerEntityManagerFactoryBean factory) {
return stepBuilderFactory
.get("posts")
.transactionManager(transactionManager)
.<Post, Post>chunk(BATCH_CHUNK_SIZE)
.reader(readers.multiPostsReader())
.writer(writers.jpaItemWriter(factory))
.faultTolerant()
.build();
}Re-running with these changes and observe the step will write Posts to MySQL!
2022-03-07 INFO 8182 --- [main] com.snimma1.Application: Started Application in 1.855 seconds (JVM running for 2.057)
2022-03-07 INFO 8182 --- [main] c.t.b.h.TaskJobLauncherCommandLineRunner: Running default command line with: []
2022-03-07 INFO 8182 --- [main] o.s.b.c.l.support.SimpleJobLauncher: Job: [SimpleJob: [name=writePosts]] launched with the following parameters: [{run.id=1}]
2022-03-07 INFO 8182 --- [main] o.s.c.t.b.l.TaskBatchExecutionListener: The job execution id 0 was run within the task execution 0
2022-03-07 INFO 8182 --- [main] o.s.batch.core.job.SimpleStepHandler: Executing step: [posts]
Having validated the reader/writer pattern above there's not much more needed to create Step definitions for the other domain objects. To do so, simply copy the Step definition above and change the model type. For example, the step to import users would look like this:
@Bean
public Step step2(
@Qualifier("appJpaTransactionManager") JpaTransactionManager transactionManager,
@Qualifier("appEntityManager") LocalContainerEntityManagerFactoryBean factory) {
return stepBuilderFactory
.get("users")
.transactionManager(transactionManager)
.<User, User>chunk(BATCH_CHUNK_SIZE)
.reader(readers.multiUsersReader())
.writer(writers.jpaItemWriter(factory))
.faultTolerant()
.build();
}An example ItemProcessor
Before we finish building out the other write steps, let's add a processing stage to format some post data. This should serve as a starting point for how to add business logic or transformations via an ItemProcessor. Recall, an ItemProcessor is simple. Given one object, some transformations occur, and another object is returned. The interface that a processor must implement is below:
public interface ItemProcessor<I, O> {
O process(I item) throws Exception;
}Therefore, defining a class PostProcessor could look like this (for example purposes we're not doing many transformations):
public class PostProcessor implements ItemProcessor<Post, Post> {
@Override
public Post process(Post in) throws Exception {
Charset charset = Charset.forName("UTF-8");
log.info("Processed post with title " + in.getTitle());
return Post.builder()
.id(in.getId())
.postType(in.getPostType())
.parentId(in.getParentId())
.acceptedAnswerId(in.getAcceptedAnswerId())
.creationDate(in.getCreationDate())
.score(in.getScore())
.viewCount(in.getViewCount())
.body(StringEscapeUtils.unescapeHtml4(in.getBody()))
.ownerUserId(in.getOwnerUserId())
.ownerDisplayName(in.getOwnerDisplayName())
.lastEditorUserId(in.getLastEditorUserId())
.lastEditorDisplayName(in.getLastEditorDisplayName())
.lastEditDate(in.getLastEditDate())
.lastActivityDate(in.getLastActivityDate())
.communityOwnedDate(in.getCommunityOwnedDate())
.closedDate(in.getClosedDate())
.title(StringEscapeUtils.unescapeHtml4(in.getTitle()))
.tags(in.getTags())
.answerCount(in.getAnswerCount())
.commentCount(in.getCommentCount())
.contentLicense(in.getContentLicense())
.build();
}
}After adding the PostProcessor to the configuration for the write post step we can see each post is being processed when running the job:
@Bean
PostProcessor postProcessor() {
return new PostProcessor();
}
@Bean
public Step step1(
@Qualifier("appJpaTransactionManager") JpaTransactionManager transactionManager,
@Qualifier("appEntityManager") LocalContainerEntityManagerFactoryBean factory,
PostProcessor postProcessor) {
return stepBuilderFactory
.get("posts")
.transactionManager(transactionManager)
.<Post, Post>chunk(BATCH_CHUNK_SIZE)
.reader(readers.multiPostsReader())
.processor(postProcessor)
.writer(writers.jpaItemWriter(factory))
.faultTolerant()
.build();
}2022-03-07 INFO 4889 --- [main] com.snimma1.processor.PostProcessor: Processed post with title Does sleeping position affect health?
2022-03-07 INFO 4889 --- [main] com.snimma1.processor.PostProcessor: Processed post with title How effective was the 2014-2015 influenza vaccination?
2022-03-07 INFO 4889 --- [main] com.snimma1.processor.PostProcessor: Processed post with title Does having too much sugary things cause headaches?Executing parallel writes
Each of the other Steps in job follows the same pattern outlined above (save for the processing step). You can find the full set of Step definitions here. What I want to focus on before recapping is the concept of parallel processing within Spring Batch.
The framework offers two modes of parallel processing:
- Single process, multi-threaded
- Multi-process
Definitions and in-depth examples of both can be found in Spring's docs here. All the data we're batching can be read and written in parallel, so an easy efficiency win would be to execute every step in unison. This is an example of single process, multi-threaded. Spring Batch steps can be sequenced using some additional tools the framework provides. By defining a Flow and providing a ThreadPool, each Step will be executed in parallel. The Java configuration to do this is below:
@Bean
public TaskExecutor taskExecutor() {
SimpleAsyncTaskExecutor executor = new SimpleAsyncTaskExecutor("batch_x");
executor.setConcurrencyLimit(CONCURRENCY_LIMIT);
return (TaskExecutor) executor;
}
@Bean
public Flow splitFlow(
@Qualifier("step1") Step step1,
@Qualifier("step2") Step step2,
@Qualifier("step3") Step step3,
@Qualifier("step4") Step step4,
@Qualifier("step5") Step step5,
@Qualifier("step6") Step step6) {
final Flow f1 = new FlowBuilder<Flow>("s1").from(step1).end();
final Flow f2 = new FlowBuilder<Flow>("s2").from(step2).end();
final Flow f3 = new FlowBuilder<Flow>("s3").from(step3).end();
final Flow f4 = new FlowBuilder<Flow>("s4").from(step4).end();
final Flow f5 = new FlowBuilder<Flow>("s5").from(step5).end();
final Flow f6 = new FlowBuilder<Flow>("s6").from(step6).end();
return new FlowBuilder<SimpleFlow>("splitFlow")
.split(taskExecutor())
.add(f1, f2, f3, f4, f5, f6)
.build();
}
@Bean
public Job importStackDumpToSql(Flow jobFlow) {
return jobBuilderFactory
.get("stackDump2SQL")
.incrementer(new RunIdIncrementer())
.start(jobFlow)
.end()
.build();
}Now we can sit back and executing the job to get an import of an entire Stack Exchange site into MySQL!
Summary
We have built out a full multi-threaded, parameterized batch job using Spring. To do so we used some open-source ItemReader & Writer implementations tailored to load Stack Exchange sites published as XML data dumps to a MySQL database.